A 特別に考慮すべき点
A Special Considerations
A.1 イプシロン
A.1 Epsilon
歴史上, 小文字のイプシロンの異体字の形には, たくさんの混乱や同意不足がありました.
Historically there has been much confusion and lack of
agreement over variant forms for lower case epsilon.
この仕様書は, 下記の定義を用いています. epsilonという名前は原文のギリシア語で用いる文字(U+03B5)として使われ, varepsilonは数学で一般的に用いるイプシロン記号の文字(U+03F5)として使われることに注意が必要です. また, この使用方法は, 似た文字の組(例えは, thetaとvartheta)の名前の付け方についても同様です. ただし, TeXやMathML2や従来のISO実体セットのユニコードへの割り当て方などで使用される名付け方の慣習とは互換性がないことに注意が必要です.
This specification uses the definitions below. Note that the
name epsilon is used for the character used in textual
Greek (U+03B5) and varepsilon used for the epsilon
symbol character more commonly used in mathematics
(U+03F5). Note that this usage is compatible with the naming of
similar pairs of characters (for example theta,
vartheta) but incompatible with the naming
convention used in TeX, MathML2 and some earlier mappings of the
ISO entity sets to Unicode.
実体名
Entity | セット名
Set | 説明
Description | ユニコード文字
Unicode Character |
|---|
| eacgr | isogrk2 | =小文字イプシロン, アクセント, ギリシア語
=small epsilon, accent, Greek | U+03AD | 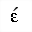 | ギリシア文字のアクセント記号付き小文字イプシロン
GREEK SMALL LETTER EPSILON WITH TONOS |
| egr | isogrk1 | =小文字イプシロン, ギリシア語
=small epsilon, Greek | U+03B5 | 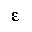 | ギリシア文字の小文字イプシロン
GREEK SMALL LETTER EPSILON |
| epsi | isogrk3 | /epsilon
/epsilon |
| epsilon | xhtml1-symbol | |
| epsiv | isogrk3 | /straightepsilon, 小文字イプシロン, ギリシア語
/straightepsilon, small epsilon, Greek | U+03F5 | 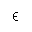 | ギリシア文字の三日月状のイプシロン記号
GREEK LUNATE EPSILON SYMBOL |
| straightepsilon | mmlalias | ISOGRK3 epsivの別名
alias ISOGRK3 epsiv |
| varepsilon | mmlalias | ISOGRK3 epsivの別名
alias ISOGRK3 epsiv |
| bepsi | isoamsr | /backepsilon R: 例のようなもの
/backepsilon R: such that | U+03F6 | 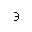 | ギリシア文字の反転した三日月状のイプシロン記号
GREEK REVERSED LUNATE EPSILON SYMBOL |
| backepsilon | mmlalias | ISOAMSR bepsiの別名
alias ISOAMSR bepsi |
| b.epsi | isogrk4 | 小文字イプシロン, ギリシア語
small epsilon, Greek | U+1D6C6 | 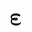 | 数学用太字の小文字イプシロン
MATHEMATICAL BOLD SMALL EPSILON |
| b.epsiv | isogrk4 | イプシロンの異体字
variant epsilon | U+1D6DC | 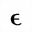 | 数学用太字のイプシロン記号
MATHEMATICAL BOLD EPSILON SYMBOL |
A.2 ファイ
Phi
ファイの状況は, イプシロンととても似ています. ただし, ユニコードの以前のバージョンが, U+03C6とU+03D5に対する字形の例を取り違えていたというより複雑な事情があります. また, 古いフォントの中には, いまだに古い慣習に従って使われているものがあります. この仕様書で使われている定義は, 下記の一覧の通りです.
The situation for phi is very similar to that of epsilon,
although with the further complication that early versions of
Unicode had the sample glyphs for U+03C6 and U+03D5 swapped
from the current usage, and some older fonts still in use follow
that older convention. The definitions used in this
specification are as listed below.
実体名
Entity | セット名
Set | 説明
Description | ユニコード文字
Unicode Character |
|---|
| phi | isogrk3 | /phi - 小文字ファイ, ギリシア語
/phi - small phi, Greek | U+03C6 | 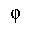 | ギリシア文字の小文字ファイ
GREEK SMALL LETTER PHI |
| phi | xhtml1-symbol | ギリシア文字の小文字ファイ
greek small letter phi |
| phgr | isogrk1 | =小文字ファイ, ギリシア語
=small phi, Greek |
| straightphi | mmlalias | ISOGRK3 phivの別名
alias ISOGRK3 phiv | U+03D5 | 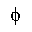 | ギリシア文字のファイ記号
GREEK PHI SYMBOL |
| phiv | isogrk3 | /varphi - 直立のファイ
/varphi - straight phi |
| varphi | mmlalias | ISOGRK3 phivの別名
alias ISOGRK3 phiv |
| b.phi | isogrk4 | 小文字ファイ, ギリシア語
small phi, Greek | U+1D6D7 |  | 数学用太字の小文字ファイ
MATHEMATICAL BOLD SMALL PHI |
| b.phiv | isogrk4 | ファイの異体字
variant phi | U+1D6DF | 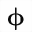 | 数学用太字のファイ記号
MATHEMATICAL BOLD PHI SYMBOL |
A.3 複数文字の実体
Multiple Character Entities
前節の一覧で示した合成文字や異体字の組み合わせ以外の, 1文字より長い文字列を置き換える, 残りの実体は下表の一覧のとおりです.
In addition to the combining and variant character combinations
listed in the previous sections,
the following table lists the remaining entity replacement texts that
consist of more than one character.
実体名
Entity | セット名
Set | 説明
Description | ユニコード文字
Unicode Character |
|---|
| fjlig | isopub | 小文字fj連字
small fj ligature | U+0066 U+006A | 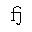 | (fj連字)
fj ligature |
| ThickSpace | mmlextra | 5/18em幅の空白
space of width 5/18 em | U+205F U+200A |  | (5/18em幅の空白)
space of width 5/18 em |
| race | isoamsb | 反転した相似, 下線
reverse most positive, line below | U+223D U+0331 | 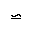 | (下線付きの)反転したチルダ
REVERSED TILDE with underline |
| acE | isoamsb | 相似, 二重下線
most positive, two lines below | U+223E U+0333 |  | (二重下線付きの)ひっくり返ったゆったりしたS
INVERTED LAZY S with double underline |
ユニコードには, アルファベット表示系の区画に含まれるfi(U+FB01)のような一般のfの連字はあるにも関わらず, fjという文字はありません. fjlig実体は, "fj"という文字の組に当てはめられます. 現在の文字入力装置は, fjという連字をフォントが提供しているなら, fjという組み合わせに対し自動的にその連字を用いるべきです.
Unicode does not have an fj character, although the other common f ligatures
such as fi (U+FB01) are contained in the Alphabetic Presentation Forms block.
The fjlig entity is mapped to the pair of characters "fj";
modern typesetting engines should automatically use the fj ligature for this
combination if the font supplies such a ligature.
ユニコードは, (5/18emを除く, 6/18em以下の全ての1/18emの倍数の幅の)空白文字を持っています. そのため, ThickSpace実体は, 空白文字の組に割り当てられています. U+2005(1/4em)が使われていたこともありました. 表示されるフォントがどの大きさでも, その差は目に見えて分かるものではないとはいえ, 1/4emは5/18emと等しくないことから上記の定義が選ばれました.
Unicode has a range of space characters (including all multiples of
1/18 em up to 6/18, except for 5/18 em) thus the ThickSpace entity is
mapped to a pair of space characters. An alternative would have been to use
U+2005 (1/4 em), but 1/4 em is not equal to 5/18 em, so the above definition was
chosen, despite the fact that the difference is unlikely to be visibly
noticeable at most typeset font sizes.
race実体とacE実体は, ユニコードがコードポイントを持っていない下線付きの文字です. そのため, 文字に下線を合成することは, 打ち消された演算子のために一画加えるのと類似した方法で行われています.
The entities race and acE denote underlined
characters for which Unicode does not have codepoints, thus combining
underline characters have been used, in a way analogous to the use of
combining strokes for negated operators.
A.4 合成文字として実装された実体
Entities Defined to be a Combining Character
合成文字から構成される文字列を置き換えた実体は下表の一覧のとおりです.
The following table lists the entity replacement texts that
consist of a combining character.
実体名
Entity | セット名
Set | 説明
Description | ユニコード文字
Unicode Character |
|---|
| DownBreve | mmlextra | (空白を伴わない)ひっくり返った短音記号
breve, inverted (non-spacing) | U+0311 | 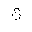 | 合成用のひっくり返った短音記号
COMBINING INVERTED BREVE |
| tdot | isotech | 文字の上の3つの点
three dots above | U+20DB |  | 文字の上に合成する3つの点
COMBINING THREE DOTS ABOVE |
| TripleDot | mmlalias | ISOTECH tdotの別名
alias ISOTECH tdot |
| DotDot | isotech | 文字の上の4つの点
four dots above | U+20DC |  | 文字の上に合成する4つの点
COMBINING FOUR DOTS ABOVE |
[Charmod-norm]でより詳しく説明していますが, 実体の展開とユニコード標準化が行われる順番によって異なった結果となる可能性があるので, 実体の文字列を合成文字で置き換えることは勧められません. この仕様書は可能な限り合成でない文字を使うようにしていますが, DownBreve, tdot, TripleDot, DotDotの場合, ユニコードにはアクセントを合成する形しかありません.
For reasons explained further in [Charmod-norm], it is
not advisable to start the replacement text of an entity with a
combining character, as then potentially different results may be
produced depending on the order in which entity expansion and Unicode
normalisation are performed. As far as possible this specification
uses non-combining characters, however, in the cases DownBreve,
tdot, TripleDot and DotDot
Unicode only has combining forms of the accents.
この仕様書の従来版は, 前の文字列と実体が合成されて展開する可能性を避けるために, これらの実体を空白で始まる文字列で置き換えるよう定義していました. しかしながら, 様々な理由からHTMLに組み入れられた実体はそこの箇所に空白を持っていません. そのため, 現在の定義は合成文字のみから構成されています. このことにより, HTMLやXHTMLは, これらの定義を用いるどの仕様書とも調和することになります.
Earlier versions of this specification defined these entities
with the replacement text starting with a space, to avoid the possibility that
the expansion of the entity combined with preceding text. However for various reasons
the entities as incorporated in HTML do not have a space here, and so the
definitions now consist just of the combining character so that HTML and XHTML
are consistent with any specifications using these definitions.
B 変更点
Changes
B.1 2014年4月10日(第2版勧告)以降の変更点
Changes since 2014-04-10 (Second Edition Recommendation)
ソースファイルをユニコード15.0に更新しました. 文字の一覧表には影響がありましたが, 生成された実体ファイルやスタイルシートには変更はありませんでした. U+FE01異体字選択用文字に対する新しい表が追加され, U+FE00の異体字セットが大きく拡張されました(それらの標準化された異体字のほとんどは, ユニコード14で加えられたものです). スクリプトのアルファベットの表は, 両方の異体字を示すように拡張されました.
Source files updated to Unicode 15.0, affecting the character tables,
but with no changes to generated entity files or stylesheets.
New table for the U+FE01 Variation selector and greatly extended set of variations in the U+FE00 table (most of these standardised variants were added at Unicode 14). The script alphabet table has been extended to show both variants.
2021年11月版のW3C手続き文書への参照を加えました.
Reference added to the November 2021 W3C Process Document.
最新のW3C公開手続きで必要とされているGitHubへのリンクを含むよう, 前書きを若干変更しました.
Some changes to the front matter including link to GitHub as
required by the latest W3C publication process.
新しいW3C文書書式に合致するようCSS書式を調整しました.
Adjustments to CSS styling to match new W3C document style.
元データの保管場所をgithubに動かしました. そのため, ログ(過去の履歴)は現在公開されています.
The source repository has been moved to github so the log is now public.
A.4 合成文字として定義された実体で説明したように, DownBreve, tdot, TripleDot, DotDotは, もはや空白で始まりません.
As detailed in A.4 Entities Defined to be a Combining Character DownBreve,
tdot, TripleDot and DotDot are no longer prefixed by a space.
B.2 2010年4月1日(第1版勧告)から2014年4月10日(第2版勧告)の間の変更点
Changes between 2010-04-01 and 2014-04-10 (First and Second Edition Recommendations)
ソースファイルをユニコード6.3に更新しました. 文字の一覧表には影響がありましたが、生成された実体ファイルやスタイルシートに変更はありませんでした.
Source files updated to Unicode 6.3, affecting the character tables,
but with no changes to generated entity files or stylesheets.
ソースファイルをユニコード6.1のアラビア数学のアルファベット(U+1EE??)のデータに対応するよう更新しました. 第3節および第4節に表を追加しました.
Source files updated Unicode 6.1 data on Arabic math alphabets (U+1EE??). Additional tables shown in Sections 3 and 4.
2 実体セットを, MathMLやHTMLで利用されているhtmlmathmlセットを強調するよう再編成しました.
Section 2 Sets of names reorganized to highlight the htmlmathml set which is used in MathML and HTML. Also link to XSL and JSON formats for the HTML MathML set.
[MathML3], [HTML5], [ユニコード]についての参考文献を更新しました.
References updated: [MathML3], [HTML5] and [Unicode].
B.3 2010年2月11日から2010年4月1日の間の変更点
Changes between 2010-04-01 and 2010-02-11
例の画像を少し改良し, ユニコードが参照している画像により一致したものを用いるようにしました.
Several example images improved, bringing them more in line with the Unicode reference images.
B.4 2009年11月17日から2010年2月11日の間の変更点
Changes between 2010-02-11 and 2009-11-17
ユニコードを内部IDを用いたU01234という形で表示する代わりに, 一貫してU+1234という記述法を使ったこと等, 様々な編集の改良を行いました.
Various editorial improvements, including using Unicode U+1234
notation more consistently rather than displaying the internal
IDs of the form U01234.
2009年11月17日の草案版で配布された結合された実体ファイルは, 2つの実体名が事例によってのみ異なっているときに, 片方のものしか含んでいないという間違いがありました. 最新版では修正しています.
The combined entities file distributed with the 2009-11-17
draft introduced an error that if two entity names differed only
by case, only one was included. This has been corrected.
HTMLやMathMLで利用可能な実体に対応する結合された実体セットhtmlmathmlを適切に提供するようにしました. XMLで定義済の実体に対応する(以前内部的に使われていた)定義済のセットを文書化しました.
The combined entity set htmlmathml corresponding to the
entities usable in HTML and MathML is now explicitly provided. The
predefined set, corresponding to the entities predefined in XML
is now documented (it was previously used internally).
xvee実体とxwedge実体は, あるユニコード(U+22C1とU+22C0)に割り当てられていましたが, 実体の説明が入れ違っていました. xveeは論理和で, xwedgeは論理積です. この間違いは, [ISO9573-13-1991]で1999年に報告されましたが, Proposed Technical Corrigendum(訳注:"提案された技術的な正誤表"という意味で, 以前の仕様書ではW3Cの正誤表へのリンクが貼ってありました.)は直されていませんでした. 実体ファイルはこの変更の影響を受けません.
The entities xvee and xwedge had the correct
Unicode assignments (U+22C1 and U+22C0) but the entity descriptions
have been swapped, xvee is logical or and xwedge is logical and.
This error in [ISO9573-13-1991] was reported in 1999,
in a Proposed Technical Corrigendum,
but not previously fixed. The entity files are unaffected by this change.
NotGreaterFullEqual実体が, 間違って打ち消された小なり記号(U+2266 U+0338)に割り当てられていたので, うち消された大なり記号(U+2267 U+0338)に訂正しました.
The entity NotGreaterFullEqual which had been erroneously assigned to
a negated less than operator (U+2266 U+0338) has been corrected to be the negated greater than operator (U+2267 U+0338).
実体ファイルへの参照を, W3Cのサーバーへからローカルな環境のコピーへに変えるために, カタログファイルの例catalogが提供するようにしました.
A sample catalog is now provided to redirect references to the entity files to copies on the local machine rather than the W3C server.
B.5 2008年7月21日から2009年11月17日の間の変更点
Changes between 2009-11-17 and 2008-07-21
html5-uppercaseセットを文書化しました
The html5-uppercase set is now documented.
正規化形式Cに合わせるため, ohm実体とangst実体をU+03A9とU+00C5に変更しました. W3C Bugzillaの記録を見て下さい.
The entities ohm and angst have changed to U+03A9 and U+00C5 to match NFC. See
w3c bugzilla entry.
誤ってU+29DAが割り当てられていたrace実体に, U+2233D U+0331の組を割り当てるようにしました. (U+223Dは, 大本のISO文書では, 回転させたチルダの代わりに回転したSの形をしている訳では全くありませんが, ユニコード5.2では大変似た文字として登場します.)
The entity race, which had been erroneously assigned U+29DA,
is now assigned the combination U+223D U+0331. (U+223D isn't
quite the shape shown in the original ISO document which is a
rotated S rather than a rotated tilde, but this appears to be
the closest character in Unicode 5.2.)
bsolhsub実体とsuphsol実体は, 以前は2つの文字の合成U+005C U+2282とU+2283 U+002Fに割り当てられていました. しかしながら, これらの実体に対応するためにはっきりと文字コードが加えられたユニコード5のU+27C8とU+27C9に割り当てるようにしました.
The entities bsolhsub and suphsol which were previously
mapped to two-character combinations U+005C U+2282 and U+2283 U+002F
are now mapped to the Unicode 5 characters that were added
specifically to support these entities, U+27C8 and U+27C9.
ユニコード5.2に対応するようにソースファイルを全て更新しました.
The source files have all been updated to match Unicode 5.2.
ThickSpace実体を, 3文字の組み合わせU+2009 U+200A U+200Aでなく, 2文字の組み合わせU+205F U+200Aに割り当てるようにしました. つまり, (3/18 + 1/18 + 1/18)emではなく, (4/18 + 1/18)emに割り当てるようにしました.
The entity ThickSpace now maps to the pair
U+205F U+200A rather than the triple U+2009 U+200A U+200A
(4/18 + 1/18)em rather than (3/18 + 1/18 + 1/18)em.
UnderBar実体を, 合成用の文字U+0332でなく, 間隔取るための文字_に割り当てました.
The entity UnderBar maps to the spacing character
_ rather than the combining character U+0332.
OverBar実体を, 長音記号U+00AFでなく, (XHTMLのoline実体に似た)間隔を取るための文字U+203Eに割り当てました.
The entity OverBar maps to the spacing character
U+203E (like the XHTML entity oline) rather than the macron character U+00AF.
epsiv実体とvarepsilon実体を, epsilon実体(U+03B5)の別名ではなく, イプシロン記号U+03F5に割り当てるようにしました.
The entities epsiv and varepsilon are now mapped to the epsilon symbol
U+03F5 rather than being aliases for the entity epsilon, U+03B5.
phiv実体とvarphi実体を, phi実体(U+03C6)の別名ではなく, ファイ記号U+03D5に割り当てるようにしました.
The entities phiv and varphi are now mapped to the phi symbol U+03D5
rather than being aliases for the entity phi, U+03C6.
B.6 2007年12月14日から2008年7月21日の間の変更点
Changes between 2008-07-21 and 2007-12-14
この文書の草案版の次の実体の定義を変更しました.
The following entity definitions have changed at this draft:
phi, lang, rang, OverParenthesis, UnderParenthesis, OverBrace, UnderBrace, lbbrk, rbbrk.
phi, lang, rang,
OverParenthesis, UnderParenthesis,
OverBrace, UnderBrace,
lbbrk, rbbrk.